Welcome back to our design patterns series! Today, we’re tackling the Repository Pattern, a data access pattern that keeps your application’s data logic organized, decoupled, and easy to maintain. If you’ve ever found your business logic tangled up with database queries or wished for an easier way to test your code, this pattern is for you.
In this post, we’ll cover:
- What the Repository Pattern is and why it matters
- A practical example to bring it to life
- How it ties into patterns like Factory and Singleton from earlier in the series
- The pros and cons of using it
- A sneak peek at what’s next
Let’s dive in!
List blog-related:
- Basic Design Pattern – P1: Understanding the Factory Pattern
- Basic Design Pattern – P2: Mastering the Singleton Pattern
- Basic Design Pattern – P3: Exploring the Repository Pattern
- Basic Design Pattern – P4: Understanding the Builder Pattern
- Basic Design Pattern – P5: Mastering Dependency Injection
- Basic Design Pattern – P6: Understanding the Observer Pattern
- Basic Design Pattern – Final : A Summary and Comparison of Six Essential Patterns
What Is the Repository Pattern?
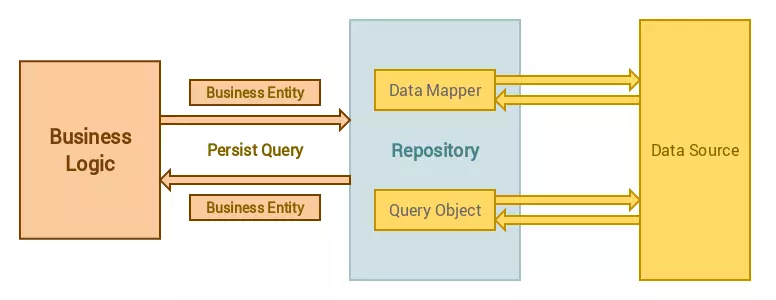
The Repository Pattern is a design pattern that simplifies how your application interacts with data. It acts as a middleman between your business logic (the domain) and your data sources (like databases, APIs, or even in-memory collections). Essentially, it provides a collection-like interface—think of it as a virtual “list” of objects—while hiding the nitty-gritty details of how that data is fetched or stored.
Picture this: instead of scattering SQL queries or API calls throughout your codebase, you ask a repository for the data you need. The repository handles the heavy lifting and returns the results, keeping your business logic clean and focused.
Core Ideas:
- Abstraction: Shields your app from the specifics of data access.
- Separation of Concerns: Lets your business logic focus on what it does best.
- Consistency: Centralizes data operations in one place.
In essence, the Repository Pattern decouples your application from its data layer, making your code more flexible and maintainable.
Why Use the Repository Pattern?
Without a pattern like this, data access logic often ends up mixed into your application’s core. Imagine a UserService class stuffed with database connection code or direct API calls. That’s a recipe for trouble:
- Tight Coupling: Changing databases (say, from MySQL to MongoDB) requires rewriting tons of code.
- Testing Headaches: You’re stuck hitting a real database during tests.
- Messy Maintenance: Data logic scattered everywhere is hard to update.
The Repository Pattern fixes this by:
- Centralizing Data Access: All data operations live in the repository, making them easier to manage.
- Decoupling: Your app talks to a repository interface, not the data source itself.
- Boosting Testability: Swap in a mock repository for lightning-fast, isolated tests.
It’s a game-changer for scalability and clean code!
Example Implementation
Let’s see the Repository Pattern in action with a simple scenario: managing user data. We’ll define a repository interface and implement it for an in-memory list. Later, you could swap this for a database implementation without touching the business logic.
Step 1: Define the Repository Interface
Start with an interface that spells out the data operations—like fetching users or adding a new one.
public interface UserRepository {
List<User> getAllUsers();
User getUserById(int id);
void addUser(User user);
void updateUser(User user);
void deleteUser(int id);
}Step 2: Implement the Repository
Now, implement this interface for an in-memory data source. This could easily become a database version later.
public class InMemoryUserRepository implements UserRepository {
private List<User> users = new ArrayList<>();
@Override
public List<User> getAllUsers() {
return users;
}
@Override
public User getUserById(int id) {
return users.stream().filter(user -> user.getId() == id).findFirst().orElse(null);
}
@Override
public void addUser(User user) {
users.add(user);
}
@Override
public void updateUser(User user) {
for (int i = 0; i < users.size(); i++) {
if (users.get(i).getId() == user.getId()) {
users.set(i, user);
return;
}
}
}
@Override
public void deleteUser(int id) {
users.removeIf(user -> user.getId() == id);
}
}Step 3: Use It in Business Logic
Here’s how your business logic uses the repository, staying blissfully unaware of where the data comes from.
public class UserService {
private UserRepository repository;
public UserService(UserRepository repository) {
this.repository = repository;
}
public void displayAllUsers() {
List<User> users = repository.getAllUsers();
users.forEach(user -> System.out.println(user.getName()));
}
public void addNewUser(User user) {
repository.addUser(user);
}
}Example with Python code:
Let’s walk through a simple Python example using the Repository Pattern. I’ll show you a scenario with a User object, and we’ll create:
- A User model
- A UserRepository interface
- A Concrete repository (e.g., using in-memory storage or database)
- A Service layer that uses the repository
1. Define the User model
from dataclasses import dataclass
@dataclass
class User:
id: int
name: str
email: str2. Define the Repository Interface
from abc import ABC, abstractmethod
from typing import Optional, List
class IUserRepository(ABC):
@abstractmethod
def get_by_id(self, user_id: int) -> Optional[User]:
pass
@abstractmethod
def list_users(self) -> List[User]:
pass
@abstractmethod
def save(self, user: User) -> None:
pa<span style="background-color: initial; font-family: inherit; font-size: inherit; color: var(--wp--preset--color--contrast);">ss</span></code><code>
</code>3. Concrete Repository (In-Memory Example)
class InMemoryUserRepository(IUserRepository):
def __init__(self):
self._users = {}
def get_by_id(self, user_id: int) -> Optional[User]:
return self._users.get(user_id)
def list_users(self) -> List[User]:
return list(self._users.values())
def save(self, user: User) -> None:
self._users[user.id] = userYou could replace this with a SQLAlchemy, MongoDB, or external API-based implementation.
4. Service Layer using the Repository
class UserService:
def __init__(self, user_repo: IUserRepository):
self.user_repo = user_repo
def create_user(self, user_id: int, name: str, email: str):
if self.user_repo.get_by_id(user_id):
raise ValueError("User already exists")
user = User(id=user_id, name=name, email=email)
self.user_repo.save(user)
def list_all_users(self):
return self.user_repo.list_users()5. Usage Example
if __name__ == "__main__":
user_repo = InMemoryUserRepository()
user_service = UserService(user_repo)
user_service.create_user(1, "Alice", "[email protected]")
user_service.create_user(2, "Bob", "[email protected]")
for user in user_service.list_all_users():
print(user)How It Shines:
- Flexibility: Switch
InMemoryUserRepositoryfor aDatabaseUserRepository—no changes needed inUserService. - Testability: Inject a mock repository during tests to fake the data layer.
- Clarity: The business logic stays focused on its job, not data plumbing.
This is the Repository Pattern’s magic in action!
Connection to Other Design Patterns
Since this is part of our series, let’s tie it back to patterns we’ve explored:
- Factory Pattern (link to Factory Pattern post): Use a factory to create repository instances. Need an in-memory repo for testing and a database repo for production? A factory can handle that.
- Singleton Pattern (link to Singleton Pattern post): For resource-intensive data sources (like a database connection), a singleton repository ensures you’re not spinning up multiple instances.
For example, a factory could churn out a singleton repository, blending both patterns for efficiency and flexibility.
Benefits and Drawbacks
Benefits
- Decoupling: Frees your app from data source specifics.
- Testability: Mock repositories make unit testing a breeze.
- Maintainability: Centralizes data logic for easier updates.
- Adaptability: Switch data sources with minimal fuss.
Drawbacks
- Complexity: Adds layers that might feel overkill for tiny projects.
- Over-Abstraction: If taken too far, it can clutter your codebase.
It’s perfect for complex or evolving apps, but for a quick script? Maybe skip it.
Conclusion and Next Steps
The Repository Pattern is a fantastic way to tame data access in your applications. By hiding the messy details behind a clean interface, it keeps your code modular, testable, and ready for change—qualities every developer craves.
Here’s what we’ve covered:
- The Repository Pattern’s role and purpose
- A hands-on example with user data
- Links to Factory and Singleton patterns
- Its upsides and downsides
Next time, we’ll explore the Builder Pattern, a handy way to construct complex objects step-by-step. Until then, give the Repository Pattern a spin in your projects and let me know how it goes. Happy coding!
Leave a Reply