Hey junior devs! By now, you’ve probably played with threads and processes in Python and seen how they can juggle multiple tasks. But creating and managing tons of threads or processes manually can get messy—think of it like hiring a new worker for every tiny job in a factory. That’s where thread pools and process pools come in. They’re like pre-hired teams ready to tackle tasks efficiently. In this blog, we’ll explore what thread pools and process pools are, how they work in Python, and when to use them. Plus, I’ll throw in some examples to make it crystal clear. Let’s dive in!
List blog-related:
- Processes, and Concurrency in Python: A Beginner’s Guide – P1
- Mastering Asyncio in Python: Single-Threaded Concurrency Made Simple – P2
- Deep Dive into Thread Pools and Process Pools in Python: Simplify Concurrency Like a Pro – P3 (final)
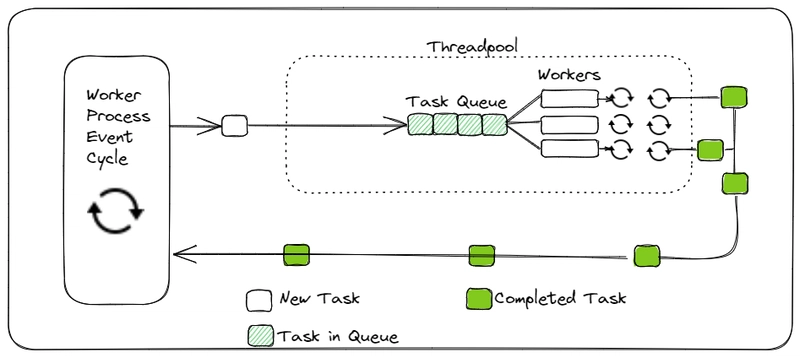
What Are Thread Pools and Process Pools?
Imagine you’re running a restaurant. Instead of hiring a new chef for every order (which would be chaotic), you have a small, fixed team of chefs who handle all the cooking. That’s the idea behind pools:
- Thread Pool: A fixed group of threads that take tasks from a queue and work on them. Once a thread finishes, it grabs the next task—no need to create new threads constantly.
- Process Pool: A fixed group of processes that do the same thing, but with separate memory spaces and true parallelism.
Python provides these through the concurrent.futures module, which gives us ThreadPoolExecutor for threads and ProcessPoolExecutor for processes. They’re higher-level tools than raw threading or multiprocessing, making concurrency simpler and more manageable.
Why Use Pools?
- Efficiency: Creating threads or processes takes time and resources. Pools reuse a set number of workers, reducing overhead.
- Control: You decide how many workers (threads or processes) run at once—no runaway chaos.
- Simplicity: Submit tasks and let the pool handle the scheduling—no manual
start()orjoin()calls.
Think of pools as a “task manager” that keeps your program organized and performant.
ThreadPoolExecutor: Handling I/O-Bound Tasks
The ThreadPoolExecutor is perfect for I/O-bound tasks—like downloading files or querying APIs—where your program spends time waiting. Since threads share memory and are lightweight, they’re ideal here, even with Python’s GIL (Global Interpreter Lock).
Here’s an example of downloading “files” with a thread pool:
from concurrent.futures import ThreadPoolExecutor
import time
def download_file(file_name):
print(f"Starting download: {file_name}")
time.sleep(2) # Simulate network delay
return f"Finished {file_name}"
# Use a thread pool with 2 workers
with ThreadPoolExecutor(max_workers=2) as executor:
# Submit tasks to the pool
files = ["file1.txt", "file2.txt", "file3.txt"]
results = executor.map(download_file, files)
# Collect and print results
for result in results:
print(result)Output:
Starting download: file1.txt
Starting download: file2.txt
Finished file1.txt
Starting download: file3.txt
Finished file2.txt
Finished file3.txtWhat’s Happening?
- We create a pool with 2 threads (
max_workers=2). - Three tasks are submitted, but only two run at a time. When one finishes, the third starts.
- The GIL doesn’t slow us down because this is I/O-bound (waiting with
time.sleep).
ProcessPoolExecutor: Crushing CPU-Bound Tasks
The ProcessPoolExecutor is your go-to for CPU-bound tasks—like heavy calculations or data processing—where you need true parallelism across multiple CPU cores. Processes bypass the GIL, making them powerful but heavier than threads.
Here’s an example of computing squares with a process pool:
from concurrent.futures import ProcessPoolExecutor
def compute_squares(n):
print(f"Computing squares up to {n}")
result = sum(i * i for i in range(n))
return result
# Use a process pool with 2 workers
with ProcessPoolExecutor(max_workers=2) as executor:
# Submit tasks to the pool
numbers = [1000000, 2000000, 3000000]
results = executor.map(compute_squares, numbers)
# Collect and print results
for result in results:
print(f"Result: {result}")Output (order may vary):
Computing squares up to 1000000
Computing squares up to 2000000
Result: 333332833333500000
Computing squares up to 3000000
Result: 1333332833333500000
Result: 4499995500001500000What’s Happening?
- We create a pool with 2 processes.
- Each process runs on a separate CPU core, computing in parallel.
- The third task waits until a process is free, then jumps in.
Thread Pool vs. Process Pool: How to Choose?
Feature |
ThreadPoolExecutor |
ProcessPoolExecutor |
|---|---|---|
Memory |
Shared (threads) |
Separate (processes) |
GIL Impact |
Limited by GIL |
Bypasses GIL |
Overhead |
Low (lightweight) |
High (heavier startup) |
Best For |
I/O-bound (e.g., network) |
CPU-bound (e.g., math) |
Max Workers |
Can be high (e.g., 10-50) |
Usually CPU cores (e.g., 4) |
- Thread Pool: Use when waiting is the bottleneck (I/O-bound).
- Process Pool: Use when computation is the bottleneck (CPU-bound).
Real-World Use Cases
- Thread Pool: Batch API Requests
- Why? Lots of waiting for network responses.
- Example: Fetching data from multiple endpoints.
from concurrent.futures import ThreadPoolExecutor
import time
def fetch_api(endpoint):
print(f"Fetching {endpoint}")
time.sleep(1) # Simulate API call
return f"Data from {endpoint}"
endpoints = ["api1.com", "api2.com", "api3.com"]
with ThreadPoolExecutor(max_workers=2) as executor:
results = list(executor.map(fetch_api, endpoints))
print(results)Output:
Fetching api1.com
Fetching api2.com
Data from api1.com
Fetching api3.com
Data from api2.com
Data from api3.com
['Data from api1.com', 'Data from api2.com', 'Data from api3.com']- Process Pool: Image Resizing
- Why? CPU-intensive work across multiple images.
- Example: Processing a batch of images.
from concurrent.futures import ProcessPoolExecutor
def resize_image(image_id):
print(f"Resizing image {image_id}")
# Simulate CPU work
[x * x for x in range(5000000)]
return f"Image {image_id} resized"
image_ids = [1, 2, 3, 4]
with ProcessPoolExecutor(max_workers=2) as executor:
results = list(executor.map(resize_image, image_ids))
print(results)Output (order may vary):
Resizing image 1
Resizing image 2
Image 1 resized
Resizing image 3
Image 2 resized
Resizing image 4
Image 3 resized
Image 4 resized
['Image 1 resized', 'Image 2 resized', 'Image 3 resized', 'Image 4 resized']Tips for Using Pools
- Set
max_workersWisely:
- For threads: More workers (e.g., 10-20) are fine for I/O tasks.
- For processes: Match your CPU core count (e.g., 4 on a quad-core) for optimal performance.
- Use
map()for Simplicity: It applies a function to a list of inputs and returns results in order. - Handle Exceptions: If a task fails, the exception propagates when you access the result.
- Context Manager (
with): Ensures the pool cleans up properly.
Final Thoughts
Thread pools and process pools are game-changers for concurrency in Python. ThreadPoolExecutor keeps I/O-bound tasks smooth and lightweight, while ProcessPoolExecutor unleashes true parallelism for CPU-bound work. They’re easier than raw threads or processes, letting you focus on your tasks—not the plumbing.
Experiment with these examples—try changing max_workers or adding more tasks. See how your machine handles it! Whether you’re scraping websites or crunching numbers, pools have you covered.
Leave a Reply